MiniBooNE Particle Identification
Introduction
In this post, I’m going to walk through about applying machine learning algorithms in particle physics. There are many available datasets ready for ML but one of a particular interest is the MiniBooNE dataset available on UCI machine learning repository. This dataset is used for a published paper from the experiment collaboration which is very interesting to read although it is somehow old. Particle Identification was part of the early success stories for machine learning and deep learning so it was applied since early 2000’s.
Data
- The dataset has been taken from UCI machine learning repository
- It has been taken from the MiniBooNE experiment conducted in the fermilab.
- A stream of muon neutrinos are fired and the detector measures the precense of electron neutrinos(signal) among the muon neutrinos(noise).
- There are 50 features in the dataset related to every detection made , however no information is given about the features.
- There are no missing values.
- The first line in the file MiniBooNE_PID.txt contains 2 space seperated values , the signal events come first, followed by the background events
- This is a binary classification problem where we want to tell wether a given signal is a electron neutrino or not.
we can download the dataset directly in our python/jupyter workspace using:
wget -O data.txt -nc --no-check-certificate https://archive.ics.uci.edu/ml/machine-learning-databases/00199/MiniBooNE_PID.txt
we will need to do some data processing to make the data ready for more steps. we are going to do the following:
- The data is stored in
data.txtwhich was downloaded from the above link. - We use the pandas library to read the data and skip the first row as it contains the number of positive and negative labels
- Create a numpy array of 1’s(electron neutrino) and 0’s(muon neutrino) which acts as our labels for the classification problem.
- Convert the input dataframe into a numpy array for the analysis.
- After having a look at the data we see that there are many features having large values. This makes the Machine Learning algorithms difficult to converge to a result. Therefore, the solution is to scale down the data.
- We just want the range to change, not the mean, or the variance so that the data still caries the information it did before scaling. Hence a good scaler to use is the minmax scaler.
- Use the train test split to split the data into training and test data sets with a default of 75% training data and 25% test data.
Lets code this
We need to import the needed packages
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
import matplotlib.pyplot as plt
define data and read it into pandas dataframe
df=pd.read_csv('data.txt',sep=' ',header=None,skiprows=1,skipinitialspace=True)
We explore data features
df.head()
0 1 2 3 4 5 6 7 8 9 ... 40 41 42 43 44 45 46 47 48 49
0 2.59413 0.468803 20.6916 0.322648 0.009682 0.374393 0.803479 0.896592 3.59665 0.249282 ... 101.174 -31.3730 0.442259 5.86453 0.000000 0.090519 0.176909 0.457585 0.071769 0.245996
1 3.86388 0.645781 18.1375 0.233529 0.030733 0.361239 1.069740 0.878714 3.59243 0.200793 ... 186.516 45.9597 -0.478507 6.11126 0.001182 0.091800 -0.465572 0.935523 0.333613 0.230621
2 3.38584 1.197140 36.0807 0.200866 0.017341 0.260841 1.108950 0.884405 3.43159 0.177167 ... 129.931 -11.5608 -0.297008 8.27204 0.003854 0.141721 -0.210559 1.013450 0.255512 0.180901
3 4.28524 0.510155 674.2010 0.281923 0.009174 0.000000 0.998822 0.823390 3.16382 0.171678 ... 163.978 -18.4586 0.453886 2.48112 0.000000 0.180938 0.407968 4.341270 0.473081 0.258990
4 5.93662 0.832993 59.8796 0.232853 0.025066 0.233556 1.370040 0.787424 3.66546 0.174862 ... 229.555 42.9600 -0.975752 2.66109 0.000000 0.170836 -0.814403 4.679490 1.924990 0.253893
Now we need to scale the data
file=open('data.txt')
y=file.readline()
file.close()
numlabels=[int(s) for s in y.split()]
ylabels=numlabels[0]*[1] + numlabels[1]*[0]
Y=np.array(ylabels)
X=df.to_numpy()
scaler=MinMaxScaler()
scaler.fit(X)
X_scaled=scaler.transform(X)
Then split the dataset into training and test sets
X_train,X_test,y_train,y_test=train_test_split(X_scaled,Y,random_state=0)
Evaluation
we are going to apply different ML algorithms on our data and will need to determine a rubric to evaluate our models. We define a function for model evaluation based on the confusion matrix. The confusion matrix is used to quantify how many of the predicted values were correct and incorrect.
Definitions
Accuracy: The number of true predictions(true 0’s and true 1’s) divided by the total number of predictions made Precicion: The number of true 1’s divided by the total number of 1’s predicted.(Basically telling us that how well have we predicted the 1’s) precision=1 if no 1’s are predicted as 0 (precision=TP/(TP+FP)) Recall: The number of true 1’s divided by the actual 1’s.(the fraction of correctly classified 1’s) . recall=1 if no 1s are predicted as 0.(recall=TP/(TP+FN)) ROC: a graph where false positive rate is plotted on the X-axis and true positive rate is plotted in the Y axis. The area under the ROC curve is a good measure of how well the algorothm has performed. A score close to 1 is a good auc(area under the curve) score.
def evaluate(y_test,y_pred,y_pred_proba):
cnf_matrix=metrics.confusion_matrix(y_test,y_pred)
print('The confusion matrix for the given model is: ')
print(cnf_matrix)
print('accuracy : ',metrics.accuracy_score(y_test,y_pred))
print('precision : ',metrics.precision_score(y_test,y_pred))
print('recall : ',metrics.recall_score(y_test,y_pred))
fpr, tpr, _ = metrics.roc_curve(y_test, y_pred_proba)
auc = metrics.roc_auc_score(y_test, y_pred_proba)
plt.figure()
plt.plot(fpr,tpr,label='Area under the curve= '+str(auc))
plt.legend(loc=4)
plt.title('ROC curve')
plt.xlabel('False positive rate')
plt.ylabel('True Positive rate')
Models
In this analysis we will try different machine learning algorithm and seek the best model among them. We will use the following models
- Logistic regression
- K-nearest Neigbhors
- Decision trees
- SVM (Support Vector Machines)
- Random Forest
Logistic regression
Logistic regression uses the sigmoid function to estimate the probability of an instance being classified as 1. The C value controls large values for weights that may lead to over fitting in the data
from sklearn.linear_model import LogisticRegression
# define the model
lr=LogisticRegression(random_state=0,max_iter=5000)
C_range={'C':[100]}
clf=GridSearchCV(lr,C_range).fit(X_train,y_train)
# print model scores
print('The score for this model is: ',clf.score(X_test,y_test))
print('the best value of parameter C is: ',clf.best_params_)
y_pred=clf.predict(X_test)
y_pred_proba=clf.predict_proba(X_test)[::,1]
# evaluate the model
evaluate(y_test,y_pred,y_pred_proba)
The output will be the following
The score for this model is: 0.8730778693566245
the best value of parameter C is: {'C': 100}
The confusion matrix for the given model is: [[22184 1268] [ 2859 6205]] accuracy : 0.8730778693566245
precision : 0.8303224943128596
recall : 0.684576345984113
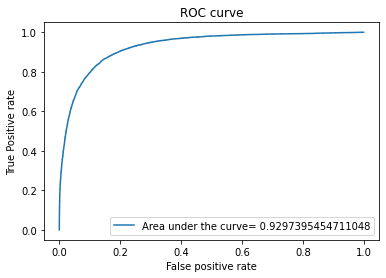
K-nearest neighbors
The K-nearest neighbors model does not actually train a model based on the data but rather stores all the training data given to it and then calculates the distance of each point from every other point.When test data is given, it classifies it as a 1 or 0 based on votes based on the chosen k(number of nearest neighbors). It is unsupervised learning algorithm
from sklearn.neighbors import KNeighborsClassifier
# define the model
knn=KNeighborsClassifier()
parameters_knn={'n_neighbors':[1,5,10,14]}
clf=GridSearchCV(knn,parameters_knn).fit(X_train,y_train)
# print model scores
print('The score for this model is: ',clf.score(X_test,y_test))
print('the best value of parameters is: ',clf.best_params_)
y_pred=clf.predict(X_test)
y_pred_proba=clf.predict_proba(X_test)[::,1]
# evaluate the model
evaluate(y_test,y_pred,y_pred_proba)
The output will be the following
The score for this model is: 0.8901463894697995
the best value of parameters is: {'n_neighbors': 14}
The confusion matrix for the given model is: [[21821 1631] [ 1941 7123]]
accuracy : 0.8901463894697995
precision : 0.8136851724925748
recall : 0.785856134157105
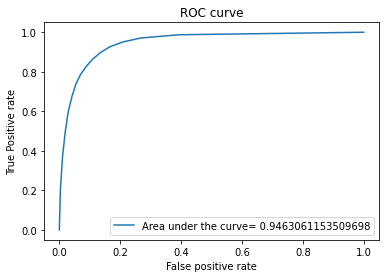
Decision Trees
A Binary Decision Tree is a structure based on a sequential decision process. Starting from the root, a feature is evaluated and one of the two branches is selected. This procedure is repeated until a final leaf is reached, which normally represents the classification target we are looking for. The model can over fit if no limit is specified on the depth the tree can go to.
from sklearn import tree
# define the model
dt=tree.DecisionTreeClassifier()
parameters_dt={'max_depth':[5,10,15]}
clf=GridSearchCV(dt,parameters_dt).fit(X_train,y_train)
# print model scores
print('The score for this model is: ',clf.score(X_test,y_test))
print('the best value of parameters is: ',clf.best_params_)
y_pred=clf.predict(X_test)
y_pred_proba=clf.predict_proba(X_test)[::,1]
# evaluate the model
evaluate(y_test,y_pred,y_pred_proba)
The output will be the following
The score for this model is: 0.908721860007381
the best value of parameters is: {'max_depth': 10}
The confusion matrix for the given model is: [[21899 1553] [ 1415 7649]]
accuracy : 0.908721860007381
precision : 0.8312323407954793
recall : 0.8438879082082965
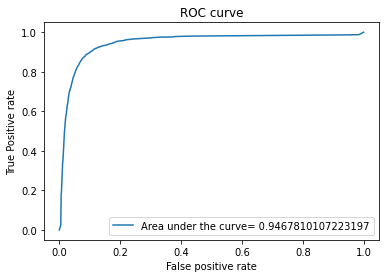
Random Forest
random forest is a classification algorithm consisting of many decisions trees. It uses bagging and feature randomness when building each individual tree to try to create an uncorrelated forest of trees whose prediction by committee is more accurate than that of any individual tree
from sklearn.ensemble import RandomForestClassifier
# define the model
rf=RandomForestClassifier(bootstrap=True)
parameters_rf={'n_estimators':[10,50,100],'max_depth':[5,10],'max_samples':[30000,40000]}
clf=GridSearchCV(rf,parameters_rf).fit(X_train,y_train)
# print model scores
print('The score for this model is: ',clf.score(X_test,y_test))
print('the best value of parameters is: ',clf.best_params_)
y_pred=clf.predict(X_test)
y_pred_proba=clf.predict_proba(X_test)[::,1]
# evaluate the model
evaluate(y_test,y_pred,y_pred_proba)
The output will be the following
The score for this model is: 0.925544347398204
the best value of parameters is: {'max_depth': 10, 'max_samples': 40000, 'n_estimators': 100}
The confusion matrix for the given model is: [[22346 1106] [ 1315 7749]]
accuracy : 0.925544347398204
precision : 0.8750988142292491
recall : 0.8549205648720212
Conclusion
In our Analysis we find “Random forest” is the best algorithm with the highest ROC value
#Machine Learning #Particle Physics #Particle Identification #Fermilab #ML