My latest project: nrepo
There is something new live on my website: melashri.net/nrepo. Recently, I have been working with different LLMs to help with coding. Usually, I spend some time copying and pasting code from different files to form a prompt and establish context. This is usually time-consuming and annoying, especially with how little context LLMs can hold. Many times, you need to start from scratch to get the best results.
I looked into many available tools for source code serialization, and I found that most of them are not really what I need. While there are many good CLI tools, sometimes I don’t want to go to the terminal and run a command to get the prompt. I wanted a tool that could be integrated with my workflow and used in a more interactive way. On my gaming Windows laptop, I don’t even have any fancy workflow, and I don’t install any of my tools (except Sublime Text). I found some web-based tools that could do the job, but they were not really what I needed. So, I forked one of them and started modifying it to fit my needs. The result is nrepo.
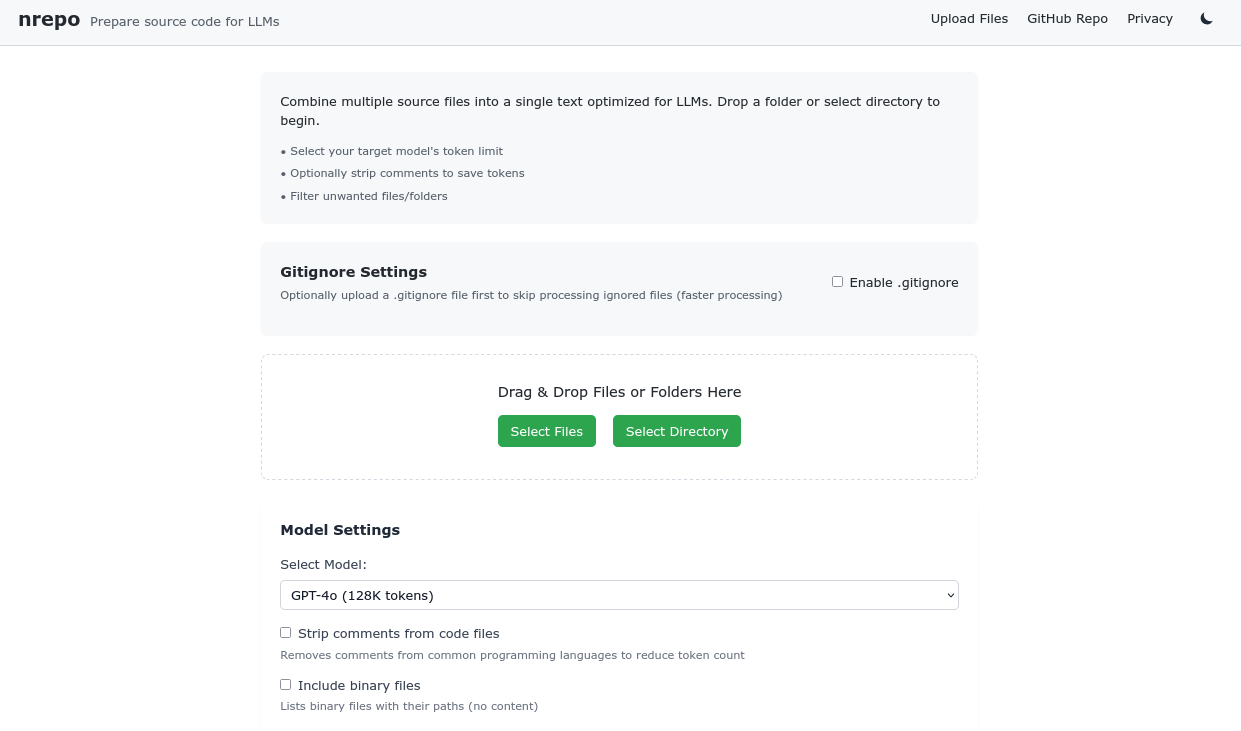
It is simple HTML/CSS/JS code that does things in a dumb way. The UI is basic and uses Tailwind CSS. I’m not a web developer and certainly not a good front-end designer, so I went with a minimalistic design. This tool is for my personal use, and I don’t want to spend time on design. I want to spend time on functionality. Better yet, I don’t want to spend time developing the tool but rather spend more time using it.
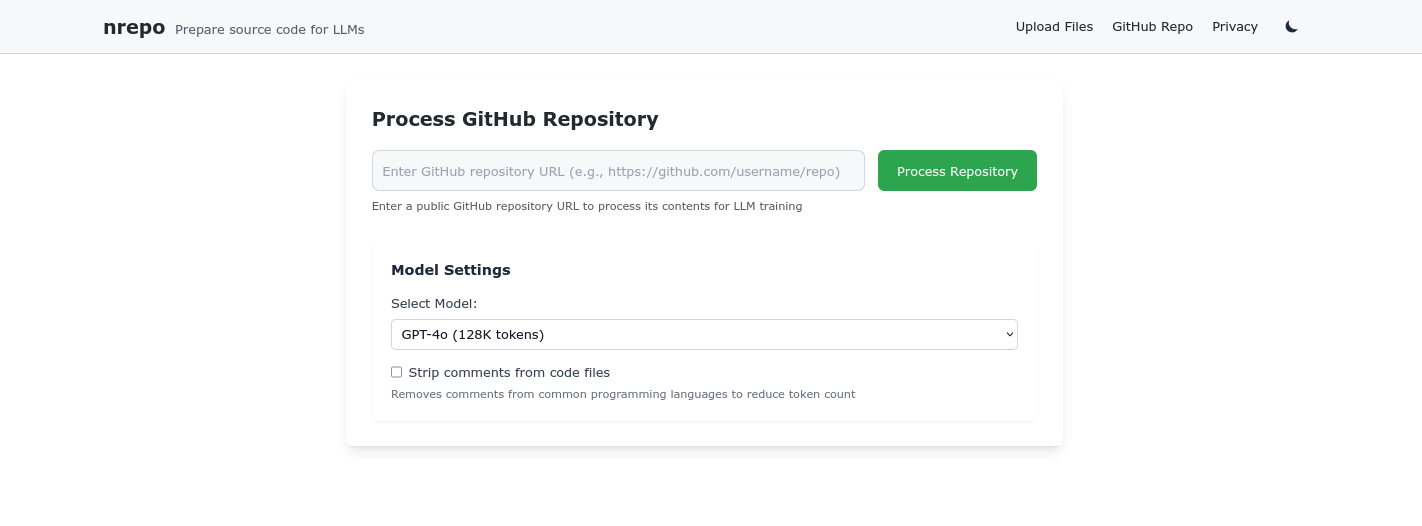
The tool is simple: you upload a folder or a couple of files, and then you get an organized list of files along with each file’s source code displayed in an organized way. At the beginning, a tree view of the files/project is shown. There is a separate page if you want to enter a GitHub repo and get the prompt. There is also a list of well-known LLMs to choose from, and all it does is compare the token length of the prompt with the LLM’s max token length to determine if the prompt can be used. The token estimation is not based on the actual token length but on the number of lines and the average line length. This is not perfect, but it’s a good estimation. I just didn’t want to spend time tokenizing the code and then counting the tokens. That goes beyond what I wanted and envisioned for this tool.
So now, all the processing happens in the browser, and the performance is not that bad. Of course, it will probably crash the browser if you try to process the Linux kernel source code. But for small projects, it works fine. And you won’t gain anything from processing large projects. The tool is for small projects and small files because LLMs do not handle large contexts well. Although Gemini models usually handle 1-2M tokens, from experience, they tend to lose track after the usual 200K tokens. I have a guess that this is why 200K is the max token limit for Claude, which I think is the best LLM for code.